Added note about this.
I dont think this is true. I have 5+ TB in my gdrive and 1TB in the virtual disk, but i think the only limits for the virtual drive is your own drive space and maybe the FAT32 maximum disk size (which afaik is bigger than 1TB)

Added note about this.
I dont think this is true. I have 5+ TB in my gdrive and 1TB in the virtual disk, but i think the only limits for the virtual drive is your own drive space and maybe the FAT32 maximum disk size (which afaik is bigger than 1TB)
Do you have a test case where GDFS is residing on a disk/volume larger than 1TiB total on a cache drive? Because all the disk management programs are showing the virtual disk as being 1TiB in size.
Again, I’m not sure if this is actually important. The main thing is to keep the cache from getting full, but I could see a case where there’s a >1TiB backup taking place, the cache doesn’t get emptied as quickly as  can push to it and it goes over some 1TiB size and breaks down even though the cache drive isn’t full.
can push to it and it goes over some 1TiB size and breaks down even though the cache drive isn’t full.
I’ve been using Drive File Stream with the cache on a pooled drive. Seems to be working well enough so far. My upload speed is only 30-40mbps so it has had upload queues of 300-500GB when I’ve backed up bigger repositories. Loads into cache quickly then gradually uploads over the course of a few days. I suppose the downside is that the new chunks aren’t reflected in the Drive storage until the upload is complete, but since I’m only uploading from a single server, it doesn’t affect me from what I can tell.
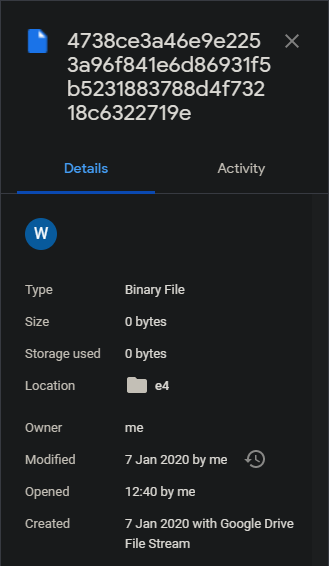
I did have a weird issue with File Stream where it popped up with a message saying one chunk couldn’t be uploaded and was moved to “Lost & Found”. See screenshot:
Not sure why, and Google doesn’t come up with much when I search for it.
Is there any way to figure out where this chunk is supposed to go? I did a check -all on the storage which didn’t come up with any missing chunks but I’m not sure if it’s causing problems I’m not aware of.
I have never heard nor had any lost and found issues with GDFS.
However what you can try, to be 100% sure all your chunks exist is to init a new repository and use a gdc:// path (ie. A Google drive Api one), then check -all on that storage.
By doing this (which will take sooo much time, better run duplicacy.exe -d -log check -all to have the debug output and see what is doing), you will see exactly what is uploaded to gdrive and eliminate the risk that your chunk may only be cached locally due to some GDFS bug.
Check -all on Drive API didn’t show any missing chunks, although I got a few instances of “chunk _______ is confirmed to exist” which I haven’t seen before.
I did a search on the lost & found chunk filename and it does appear to be available on gdrive in File Stream and the web interface. However, on the web interface, the file says that it’s 0 bytes, whereas on File Stream in Windows Explorer it shows 4.04MB.
What’s the best way to verify the integrity of this chunk? Should I overwrite it with the file in the lost & found?
What I would do is copy the 4MB chunk directly off of the File Stream with Windows Explorer to a temporary location on a local drive and binary compare or compare its hash with the chunk in your ‘Lost & Found’. If they’re the same, delete the chunk on File Stream and copy back your temporary copy (or the one in Lost & Found).
To be honest, though, the only way to be sure of the integrity of the backup is to do a check -files although I advise only to check the latest revision as otherwise it’ll check all the revisions one by one.
If your backup size is quite large, you might want to test a restore instead coz then you can resume an aborted restore.
To save even more bandwidth - because of deduplication - and only if you have the disk space, doing a copy to a new local storage would be more efficient, and then you could check -files or restore directly off of the local copy.
Seems like they’re different; the lost & found chunk shows as 0.2MB larger size on disk.
The chunk in question doesn’t exist on my local backup storage, so I assume it’s from one of the repositories I backup directly to Google Drive. I’ll do as you suggested and copy them to a new local storage and do some checks from there.
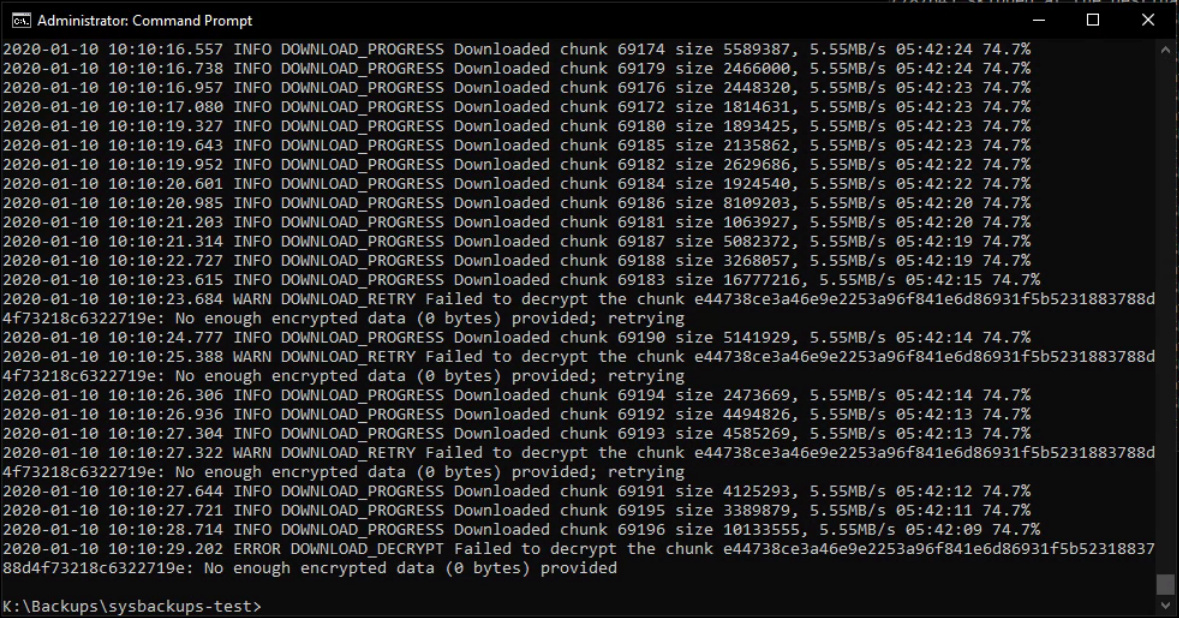
As expected, the chunk in question wasn’t uploaded properly and caused the restore operation to fail. After I replaced it with the one from lost & found, I was able to resume the restore operation, which completed successfully.
Hope that helps anyone else who has the same issue in the future.
I’m curious why this happened? could it be something that did which GDFS didn’t like, or is this a real bug in GDFS?
I have had some weird bugs with GDFS and talked to google support folks but I believe they were all fixed after I managed to repro them consistently.
No idea, it only happened to that one chunk. Hasn’t happened again in the few days since then for any of my backups. I don’t think it would have been anything on the part of Duplicacy, since it was just writing to the local cache. I had a lot of data stored in the cache queued for upload, probably a couple hundred gigabytes. Evidently, there was nothing wrong with the chunk itself since I was able to restore the backup after I manually replaced the empty chunk.
I did change the GDFS cache directory to a Drivepool of SSDs to expand the amount of data I could upload without filling the cache drive completely. Perhaps that had something to do with it? It only happened once in >1TB of uploads, though. I even rebalanced the pool a few times mid-upload to see if it would throw it off, but didn’t have any issues.
I would have no idea how to reproduce the error since I don’t recall doing anything in particular at the time that it occurred. I can’t even say for sure whether Duplicacy was running at the time, or if GDFS was just working through the upload queue (iirc it reached around 300,000 files at some point).
I don’t think this huge size was an issue, as with my last computer, i have had more than 500GB and a few million chunks to upload via GDFS in a single revision at one point, and they were all stored in the cache and uploaded slowly.
After some time they were all uploaded successfully ¯\_(ツ)_/¯ afaict. I will however run a restore for all my storages, just to make really sure that shit didn’t hit the fan.
@gchen wdyt, is there a way to make either check or backup to local drive even smarter than they currently are so that the find chunks which are 0 sized? (even though i’m asking this, i’m not sure implementing such a check will help in this particular case :-?)
I only noticed today that there was a ‘notifications’ tab on the GDFS interface, which contained the following message:
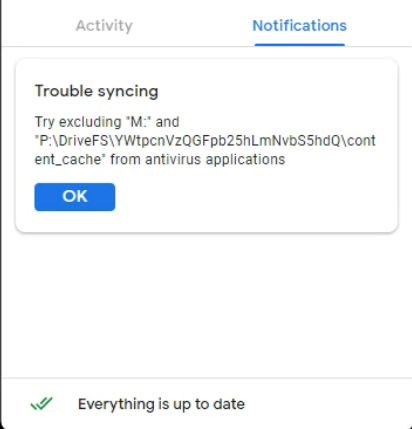
M: being the mounted GDFS drive and P:\DriveFS… being the GDFS cache directory.
At least with this particular issue, it was easy enough to resolve since:
a) There was a clear error message detailing which file wasn’t uploaded
b) It uploaded an empty chunk with the correct filename which made it possible to locate the correct directory to place the chunk from lost & found
I suppose it would be much worse if it happened for thousands of chunks. I did restore a few other snapshots that didn’t use the missing chunk and haven’t run into errors yet, so fingers crossed it’s just that one isolated event.
For now, I’ve added a Windows Defender exclusion to the GDFS drive and cache as recommended by the error message. I noticed the Defender process uses up quite a bit of resources when GDFS is running so maybe it will help in that regard as well.
I think this would be a smart idea actually…
I’ve encountered a handful of situations where I’ve seen missing chunks, 0-byte chunks, and even one chunk that had totally the wrong content*.
Then again, in these instances I am using Duplicacy in a fairly heavy-duty way - copying large Vertical Backup storages, with lots of fixed sized chunks, to another sftp storage. I’ve had no issues with my own personal Duplicacy backups, though.
But yep, I’ve witnessed a few instances where I’ve had 0-byte chunks on the destination storage and had to fix it by removing the chunk and removing the revisions in \snapshots and re-copy that particular revision. It should be a very simple additional check on its file size.
I think before I did suggest a possible improvement whereby the chunk file names could be appended with extra metadata - such as the hash of the chunk. (Since this is the method by which Duplicacy has a database-less architecture.) If not a hash, then maybe chunk size in bytes? A check for 0-byte chunks is certainly useful, but an exact match maybe more important given that @Akirus’s experience has shown a 0.2MB discrepancy.
*Edit: So yea… I actually had a chunk where the binary contents was completely different to the original storage where I copied it from. Yet the header had the ‘duplicacy<NUL>’ string at the beginning, so it wasn’t totally corrupted. Had to re-copy the chunk manually. Very puzzled by that!
I get “Failed to list the directory: open G:/: Access is denied.” when trying to do this. Is it because I have Duplicacy Web 1.3.0 running as a Windows service?
You cannot create folders directly in G, you must create your folder (the storage) at least in G:\My Drive\.
To test this, try in explorer to create a folder directly in G: it should give you an error.
Sorry, I wasn’t clear. I already have a folder in my Google drive. The problem is I cannot browse to it from Duplicacy Web because I get the error I mentioned when trying to browse to the existing folder.
Since you have running as a windows service, it could be that it’s running when you’re not logged in (note: i do not know if works w/o user login).
Afair, GDFS only runs when a user is logged in, so it could be that is trying to access that folder/drive when it doesn’t exist.
Are backups working while logged in?
@gchen do you have any ideas here?
Sitting at a computer now so I can give more context. I’m running Duplicacy web edition on a a couple of windows computers and a Linux server. I’ve got backups running with B2, Google Drive and local storage backup repositories. Backups are running without problems whether I’m logged in or not.
After reading this post, I became interested in testing whether switching from the “Google Drive” back end to the “Google Drive File Stream” method discussed above would make sense for me. I already have all the pieces in place so I thought trying this would be relatively simple. But I don’t get very far.
I’ve created a folder in my Google Drive where I want to store the backups. On my system this folder is at G:\My Drive\DuplicacyBackups\
But I’m not getting anywhere. On the Duplicacy web interface, when I try to initialize the storage i get the earlier mentioned error.
In other words this error happens when logged in and just browsing to the directory via the web interface. I do not have any issues browsing to that folder in Windows Explorer
Thank you for the much more detailed explanation. From what you’re describing, I believe this is a web-ui version limitation, maybe in the way it tries to list directory contents, since G:/ is not accessible for writing.
I do have a workaround, if you want to try that (not sure if it really works, but might be worth a try).
C:\My Drive\DuplicacyBackups\ and init the storage there.'s configuration folder.I believe by doing these steps, you work around the folder access limitation from above.
I’ve tried this as per your instructions. After changing the storage path I’ve created a check job and this fails when it runs.
Running check command from C:\ProgramData/.duplicacy-web/repositories/localhost/all
Options: [-log check -storagename -threads 7 -a -tabular]
2020-06-03 17:33:36.387 INFO STORAGE_SET Storage set to G:/My Drive/DuplicacyBackups
2020-06-03 17:33:36.388 ERROR STORAGE_CREATE Failed to load the file storage at G:/My Drive/DuplicacyBackups: CreateFile G:/My Drive/DuplicacyBackups: Access is denied.
Failed to load the file storage at G:/My Drive/DuplicacyBackups: CreateFile G:/My Drive/DuplicacyBackups: Access is denied.