
Not sure if this is a known issue (I’m new to Duplicacy), but in the Storage screen the charts aren’t rendering any data (Size / Revisions / Chunks). Tried Safari and Crome, same issue:
@joe can you view the page source to see if there are any chart data? They should be like this:
Chartist.Line('#sftpChartSize', {
labels: [ "Dec21", "Dec22", "Dec23", "Dec24", "Dec25", "Dec26", "Dec27", "Dec28", "Dec29", "Dec30", "Dec31", "Jan01", "Jan02", "Jan03", "Jan04", "Jan05", "Jan06", "Jan07", "Jan08", "Jan09", "Jan10", "Jan11", "Jan12", "Jan13", "Jan14", "Jan15", "Jan16", "Jan17", "Jan18", ],
series: [
[ 25717374976 , null , null , null , null , null , null , null , null , null , 25890390016 , 25909264384 , 25974276096 , null , 26020413440 , 26071793664 , null , null , null , null , 26186088448 , null , null , null , null , 26708279296 , 26742882304 , 26742882304 , 26742882304 , ],
[ 8298430464 , null , null , null , null , null , null , null , null , null , 8333033472 , 8352956416 , 8352956416 , null , 8381267968 , 8381267968 , null , null , null , null , 8429502464 , null , null , null , null , 8434745344 , 8434745344 , 8434745344 , 8434745344 , ],
[ 12358516736 , null , null , null , null , null , null , null , null , null , 12495880192 , 12495880192 , 12560891904 , null , 12577669120 , 12630097920 , null , null , null , null , 12695109632 , null , null , null , null , 13213106176 , 13247709184 , 13247709184 , 13247709184 , ],
[ 2283798528 , null , null , null , null , null , null , null , null , null , 2283798528 , 2283798528 , 2283798528 , null , 2283798528 , 2283798528 , null , null , null , null , 2283798528 , null , null , null , null , 2283798528 , 2283798528 , 2283798528 , 2283798528 , ],
[ 4399824896 , null , null , null , null , null , null , null , null , null , 4399824896 , 4399824896 , 4399824896 , null , 4399824896 , 4399824896 , null , null , null , null , 4399824896 , null , null , null , null , 4399824896 , 4399824896 , 4399824896 , 4399824896 , ],
[ 1090519040 , null , null , null , null , null , null , null , null , null , 1090519040 , 1090519040 , 1090519040 , null , 1090519040 , 1090519040 , null , null , null , null , 1090519040 , null , null , null , null , 1090519040 , 1090519040 , 1090519040 , 1090519040 , ],
]},
Is there any documentation/write up that explains the relation between CLI, GUI and Web edition versions?
I have two GUI licenses, running 20+ jobs. Are those jobs from Windows GUI “compatible” with Web edition or I would have to recreate them if I want to use Web edition?
@gchen yes the page source does show chart data similar to what you quoted.
I had this problem in .8 and it persists with .10, and it the chart doesn’t render in both Safari and Chrome.
Here’s the source code snippet:
Chartist.Line('#Duplicacy.WasabiChartSize', {
labels: [ "Jan05", "Jan06", "Jan07", "Jan08", "Jan09", "Jan10", "Jan11", "Jan12", "Jan13", "Jan14", "Jan15", "Jan16", "Jan17", "Jan18", "Jan19", ],
series: [
[ 133997527040 , 284708306944 , 486752124928 , 617943662592 , 716865273856 , 824981848064 , 848934469632 , 941080182784 , null , null , 998911246336 , 998918586368 , 1046934978560 , 1046934978560 , 1046934978560 , ],
[ 133990187008 , 133990187008 , 133990187008 , 133990187008 , 133990187008 , 140911837184 , 140911837184 , 140911837184 , null , null , 140911837184 , 140911837184 , 188928229376 , 188928229376 , 188928229376 , ],
[ null , null , null , null , null , 472784044032 , 472784044032 , 472784044032 , null , null , 472784044032 , 472791384064 , 472791384064 , 472791384064 , 472791384064 , ],
[ null , null , null , null , null , null , null , null , null , null , 516253810688 , 516253810688 , 516253810688 , 516253810688 , 516253810688 , ],
]},
{
axisY: {
labelInterpolationFnc: function(value) {
return formatBytes(value);
},
},
chartPadding: { left: 40, top: 20, },
lineSmooth: Chartist.Interpolation.cardinal({
fillHoles: true,
}),
low: 0,
});
Chartist.Line('#Duplicacy.WasabiChartRevision', {
labels: [ "Jan05", "Jan06", "Jan07", "Jan08", "Jan09", "Jan10", "Jan11", "Jan12", "Jan13", "Jan14", "Jan15", "Jan16", "Jan17", "Jan18", "Jan19", ],
series: [
[ 1 , 1 , 1 , 1 , 1 , 3 , 3 , 3 , null , null , 4 , 5 , 6 , 7 , 8 , ],
[ 1 , 1 , 1 , 1 , 1 , 2 , 2 , 2 , null , null , 2 , 2 , 3 , 3 , 3 , ],
[ null , null , null , null , null , 1 , 1 , 1 , null , null , 1 , 2 , 2 , 2 , 3 , ],
[ null , null , null , null , null , null , null , null , null , null , 1 , 1 , 1 , 2 , 2 , ],
]},
{
chartPadding: { left: 40, top: 20, },
lineSmooth: Chartist.Interpolation.cardinal({
fillHoles: true,
}),
low: 0,
});
Chartist.Line('#Duplicacy.WasabiChartChunk', {
labels: [ "Jan05", "Jan06", "Jan07", "Jan08", "Jan09", "Jan10", "Jan11", "Jan12", "Jan13", "Jan14", "Jan15", "Jan16", "Jan17", "Jan18", "Jan19", ],
series: [
[ 27138 , 56912 , 97746 , 123977 , 143484 , 164648 , 169321 , 187191 , null , null , 198182 , 198186 , 207958 , 207958 , 207958 , ],
[ 27136 , 27136 , 27136 , 27136 , 27136 , 28673 , 28673 , 28673 , null , null , 28673 , 28673 , 38445 , 38445 , 38445 , ],
[ null , null , null , null , null , 94391 , 94391 , 94391 , null , null , 94391 , 94395 , 94395 , 94395 , 94395 , ],
[ null , null , null , null , null , null , null , null , null , null , 101247 , 101247 , 101247 , 101247 , 101247 , ],
]},
{
axisY: {
labelInterpolationFnc: function(value) {
return formatNumber(value);
},
},
chartPadding: { left: 40, top: 20, },
lineSmooth: Chartist.Interpolation.cardinal({
fillHoles: true,
}),
low: 0,
});
$('a[data-toggle="tab"]').on('shown.bs.tab', function (e) {
target = $(e.target).attr("href");
$(".tab-pane").each(function() {
name = "#" + $(this).attr("id");
if (name != target) {
return;
}
($(this)).find('.ct-chart').each(function (i, e) {
e.__chartist__.update();
});
});
})
$(":input").on("input", inputChanged)
});
Quick update… I was able to resolve my storage graph not rendering.
It turns out, Duplicacy doesn’t like periods in storage names. I had my storage set to “Duplicacy.Wasabi” but when I renamed it to “Duplicacy-Wasabi” and ran a check, the storage graph now renders successfully.
Maybe Duplicacy should restrict periods in storage names, or alternatively fix the code so that a period doesn’t break the graph? Either way, removing the period fully fixed my issue.
3 Likes
This has the potential to create a bunch of ugly long filenames but it may in fact be necessary, as though it’s not specifically stated above and I swear I saw mention of this before but cannot find it…
Parallel backups are creating log files with the same name and thus only one survives.
When I click on or hover over one of the two parallel backup jobs, they link to the same log URL. The other log file seems to be missing.
Regarding parallel jobs… I’m wondering if Duplicacy shouldn’t approach this feature in a slightly different way.
When I started using this feature a day or so ago, I tried enabling it on just one job - expecting it to run in parallel to all others - but it doesn’t. You have to click a second job (or re-order the schedule so the parallel one is last?). Now this may sound reasonable, but it may not provide the sort of parallelism that you might want and need, i.e. parallel jobs running between different physical disks only.
Let’s say I have the following repositories:
C:/Users/Darren
E:/Darren
E:/Blah
E:/Progs
I want the first job to run in parallel to the other 3, but the three on E should run sequentially.
At the moment, if parallel is unticked, that job won’t run if any other Duplicacy instance is running - regardless of if that other instance was meant to be parallel or not. However, I think that should change to not run unless another instance is a parallel job. i.e. it should look to see if any Duplicacy processes are flagged as parallel and ignore them.
Or maybe there’s a better way. Maybe the tickbox could be tri-state: ticked, unticked, greyed out (which means indifferent, as described above).
To be honest, the main benefit of running parallel imo is to make more efficient use of disk I/O, and so long as jobs on the same physical hard drive don’t run in parallel, but those on different physical disks can, perhaps the parallel tickbox should be moved from individual jobs to a single tickbox on the schedule.
Then Duplicacy can work out on its own which jobs should be parallelised.
@joe, right, the dot is a special CSS selector so #Duplicacy.WasabiChartSize won’t find the graph correctly. I’ll add a check to the storage name to make sure such characters won’t be allowed.
I would like to switch my current license to a new computer running Duplicacy Web Eddition. How do i reveal the Hostname so i can transfer it in my Account?
EDIT
I found the solution in another thread:
On linux you simply enter “hostname” in the console
It would be handy if Duplicacy Web would show the Hostname somewhere if possible.
I came across something that is at least unexpected behavior, if not a bug. If I rename a schedule, all of the history for that schedule is lost in the “Activities” timeline in the dashboard.
When an access error occurs:
Running backup command from /root/.duplicacy-web/repositories/localhost/0 to back up test
Options: [-log backup -storage test -stats]
2019-01-23 01:14:57.360 INFO REPOSITORY_SET Repository set to test
2019-01-23 01:14:57.360 INFO STORAGE_SET Storage set to /storage
2019-01-23 01:14:57.370 INFO BACKUP_START No previous backup found
2019-01-23 01:14:57.370 INFO BACKUP_INDEXING Indexing /root/.duplicacy-web/repositories/localhost/0/test
2019-01-23 01:14:57.370 WARN LIST_FAILURE Failed to list subdirectory: open /root/.duplicacy-web/repositories/localhost/0/test: no such file or directory
2019-01-23 01:14:57.487 WARN SKIP_DIRECTORY Subdirectory cannot be listed
2019-01-23 01:14:57.491 INFO BACKUP_END Backup for /root/.duplicacy-web/repositories/localhost/0/test at revision 1 completed
2019-01-23 01:14:57.491 INFO BACKUP_STATS Files: 0 total, 0 bytes; 0 new, 0 bytes
2019-01-23 01:14:57.491 INFO BACKUP_STATS File chunks: 0 total, 0 bytes; 0 new, 0 bytes, 0 bytes uploaded
2019-01-23 01:14:57.491 INFO BACKUP_STATS Metadata chunks: 3 total, 8 bytes; 2 new, 6 bytes, 24 bytes uploaded
2019-01-23 01:14:57.491 INFO BACKUP_STATS All chunks: 3 total, 8 bytes; 2 new, 6 bytes, 24 bytes uploaded
2019-01-23 01:14:57.491 INFO BACKUP_STATS Total running time: 00:00:01
2019-01-23 01:14:57.491 WARN BACKUP_SKIPPED 1 directory was not included due to access errors
The UI marks the backup run as a success. Which is wrong. Because backup failed.
I have to disagree here. This is in line with what the CLI does, and this is what i would also expect:
2019-01-23 01:14:57.491 INFO BACKUP_END Backup for /root/.duplicacy-web/repositories/localhost/0/test at revision 1 completed <- as you can see from here the backup completed, which means this was a successful run.
It is true that that 1 directory (the only one to backup) was not listed hence 0 files were backed up, but still the backup itself was a success because no errors happened.
That’s the thing - the repository was selected and there were files in there, outside of .duplicacy-web. And yet, it failed to find something within its own .duplicacy-web folder and then failed to pick up those files. Nuking that backup object and creating a new one succeeded, so I’m not sure what was the issue there, and perhaps now it is too late and not sufficient data to triage it.
In other words, from the user perspective, who selected files, pressed backup, and software said “All good” when in reality nothing was done, and had I not clicked the link to look at the log file I would not have known.
I think any failure to pick up files shall be fatal. User selected that file, and if it is unreadable – something shall be done about that. At least a warning.
1 Like
If these won’t be considered errors, could the UI be made to at least say that it “completed with warnings” (or something similar) – since that’s what Duplicacy considers these file I/O errors?
3 Likes
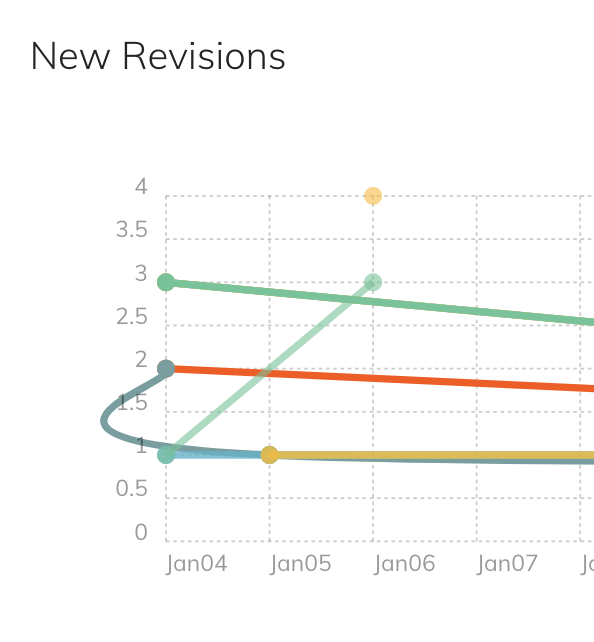
I don’t know if any more examples of wonky line smoothing are needed, but here’s another real-world one. Smoothed lines might look pretty for screenshots under certain scenarios, but they’re not accurate.
4 Likes
Hahah that’s so comical. 
But yes, that particular chart needs bar graphs instead.
Not least because the first and most recent revision count, e.g. at the start of the day will be 0 or low, a line - curvy or straight - just doesn’t make sense. They’re supposed to be independent values anyway.
4 Likes
LOL, can’t stop laughing.  Made my day!
Made my day!
1 Like
Security issue: Once I log in from one browser session, anybody can open another browser session and is not prompted to login again.
Also, there should be logout button.
1 Like
Inconsistency:
Executable is called duplicacy_web
but the config directory is called ~/.duplicacy-web
During first launch the duplicacy_web seems to generate an identifying number and downloads a license for that machine:
Duplicacy Web Edition Beta 0.2.10 (5771BE)
Starting the web server at http://[::]:3875
2019/01/24 23:40:15 A new license has been downloaded for 093e2fd5198e
When running duplicacy in the docker container this ID changes after container is re-created, even though /etc/machine-id is preserved (manually restored).
Because container does not have an identity the specific instance of duplicacy should not use discardable container data.
Would it be possible to implement a way to control how duplicacy computes that identifying information or have an option to preserve it in configuration directory once computed? (in duplicacy.json, environment variable, any other way)?
Otherwise every time new container is created it will pull a new license and I’m not sure what will happen when user would actually need to activate the product.