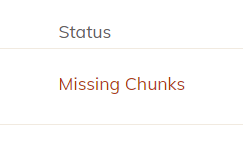
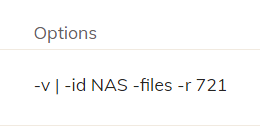
Thanks, Droolio, for helping me with this. I managed to kick off /.duplicacy-web/bin/duplicacy_linux_x64_2.7.0 -log -v check -storage pcloud -id NAS -files -r 721
(For some reason, I had to manually enter the webDAV and storage passwords, though)
Listing the chunks went fine, I guess:
2020-10-04 03:10:11.806 INFO SNAPSHOT_CHECK 1 snapshots and 1 revisions
2020-10-04 03:10:11.870 INFO SNAPSHOT_CHECK Total chunk size is 3722G in 3302176 chunks
2020-10-04 03:10:32.805 TRACE SNAPSHOT_VERIFY christoph/.identity
2020-10-04 03:11:00.852 TRACE WEBDAV_ERROR URL request 'PROPFIND chunks/f3/4b0d266bb39d9b870d01c8be4858f9f45f4b3375589f9faf2ecade9de67341' returned an error (Propfind https://webdav.pcloud.com/Backup/Duplicacy/chunks/f3/4b0d266bb39d9b870d01c8be4858f9f45f4b3375589f9faf2ecade9de67341: EOF)
2020-10-04 03:11:24.079 TRACE SNAPSHOT_VERIFY christoph/20161021_084341.mp4
Checking the files went fine for a while but then errors started pouring in:
2020-10-04 03:30:15.199 TRACE SNAPSHOT_VERIFY christoph/android backup/BCDAS-20120415-1309/nandroid.md5
2020-10-04 03:34:28.762 TRACE SNAPSHOT_VERIFY christoph/android backup/BCDAS-20120415-1309/system.img
2020-10-04 03:35:31.685 TRACE WEBDAV_ERROR URL request 'GET chunks/7d/d274e5bf88bdfdd0e0f089b9f0dacf47b2d5ec22584e13e3e177b5cb3f46f2' returned an error (Get https://webdav.pcloud.com/Backup/Duplicacy/chunks/7d/d274e5bf88bdfdd0e0f089b9f0dacf47b2d5ec22584e13e3e177b5cb3f46f2: EOF)
2020-10-04 03:38:45.678 TRACE WEBDAV_ERROR URL request 'GET chunks/da/c1886b7c878723dd866f8fdd77854c7daf218239687b0eb046b9a05b345795' returned an error (Get https://webdav.pcloud.com/Backup/Duplicacy/chunks/da/c1886b7c878723dd866f8fdd77854c7daf218239687b0eb046b9a05b345795: EOF)
2020-10-04 03:40:07.030 TRACE WEBDAV_ERROR URL request 'GET chunks/f6/bad4e3a2d417092df81819b9986dd886e08efb0d1ac742d31f7eaf110aaa9b' returned an error (Get https://webdav.pcloud.com/Backup/Duplicacy/chunks/f6/bad4e3a2d417092df81819b9986dd886e08efb0d1ac742d31f7eaf110aaa9b: EOF)
2020-10-04 03:42:47.744 TRACE WEBDAV_ERROR URL request 'GET chunks/1e/61178362132f44bc99e0e54336fd364c1ae359b40a69f839e328b44cc72ced' returned an error (Get https://webdav.pcloud.com/Backup/Duplicacy/chunks/1e/61178362132f44bc99e0e54336fd364c1ae359b40a69f839e328b44cc72ced: EOF)
2020-10-04 03:51:18.611 TRACE WEBDAV_ERROR URL request 'GET chunks/4e/78a5775244f3eebc2921e6ff2e316b56415c3cdcd5b1ce32ba58d47c5dc569' returned an error (Get https://webdav.pcloud.com/Backup/Duplicacy/chunks/4e/78a5775244f3eebc2921e6ff2e316b56415c3cdcd5b1ce32ba58d47c5dc569: EOF)
2020-10-04 03:52:39.345 TRACE WEBDAV_ERROR URL request 'GET chunks/ca/35fee822a1f7466d45b42cb09d65edd520351912789c6893f5919ced574b57' returned an error (Get https://webdav.pcloud.com/Backup/Duplicacy/chunks/ca/35fee822a1f7466d45b42cb09d65edd520351912789c6893f5919ced574b57: EOF)
2020-10-04 03:53:01.641 TRACE WEBDAV_ERROR URL request 'GET chunks/ca/35fee822a1f7466d45b42cb09d65edd520351912789c6893f5919ced574b57' returned an error (Get https://webdav.pcloud.com/Backup/Duplicacy/chunks/ca/35fee822a1f7466d45b42cb09d65edd520351912789c6893f5919ced574b57: EOF)
2020-10-04 03:53:24.063 INFO WEBDAV_RETRY URL request 'GET chunks/ca/35fee822a1f7466d45b42cb09d65edd520351912789c6893f5919ced574b57' returned status code 403
2020-10-04 03:58:19.922 TRACE WEBDAV_ERROR URL request 'PROPFIND chunks/14/97a547984e7771dfcf0e64daddcb52e8c90e0b4aeec3daaddc8cfbb1a6d8cd' returned an error (Propfind https://webdav.pcloud.com/Backup/Duplicacy/chunks/14/97a547984e7771dfcf0e64daddcb52e8c90e0b4aeec3daaddc8cfbb1a6d8cd: EOF)
2020-10-04 03:59:00.852 TRACE WEBDAV_ERROR URL request 'PROPFIND chunks/56/1f82e07c7a1e8f993ec053654958c2c8a17151e707784fbb281f0cc2750dc5' returned an error (Propfind https://webdav.pcloud.com/Backup/Duplicacy/chunks/56/1f82e07c7a1e8f993ec053654958c2c8a17151e707784fbb281f0cc2750dc5: EOF)
2020-10-04 04:05:55.963 TRACE WEBDAV_ERROR URL request 'PROPFIND chunks/56/0f1c6e0cec5db5fc99455f9f8ceaf73b28bf5f5746db1fa5965692f261557a' returned an error (Propfind https://webdav.pcloud.com/Backup/Duplicacy/chunks/56/0f1c6e0cec5db5fc99455f9f8ceaf73b28bf5f5746db1fa5965692f261557a: EOF)
2020-10-04 04:10:54.396 TRACE WEBDAV_ERROR URL request 'PROPFIND chunks/41/183a105c031f1c9ed2f891a940d2157cef22e2b4c5b4448c1b2fa010329711' returned an error (Propfind https://webdav.pcloud.com/Backup/Duplicacy/chunks/41/183a105c031f1c9ed2f891a940d2157cef22e2b4c5b4448c1b2fa010329711: EOF)
2020-10-04 04:12:55.458 TRACE WEBDAV_ERROR URL request 'GET chunks/34/2a7a0436036f338c7bfe930d192880a89aa8dbcc56606ec91e03888c4238b9' returned an error (Get https://webdav.pcloud.com/Backup/Duplicacy/chunks/34/2a7a0436036f338c7bfe930d192880a89aa8dbcc56606ec91e03888c4238b9: EOF)
2020-10-04 04:15:05.613 TRACE WEBDAV_ERROR URL request 'PROPFIND chunks/93/2096afe9d943c9ca458a42a6667fc03d9450c23553bd9453280b62e010808a' returned an error (Propfind https://webdav.pcloud.com/Backup/Duplicacy/chunks/93/2096afe9d943c9ca458a42a6667fc03d9450c23553bd9453280b62e010808a: EOF)
Over the course of about 7 hours, the output continues like that but in total it is only about 1-200 errors. But there are no positive reports about files having been checked either. So I’m not sure whether this means duplicacy is slowing down because of backoff or what.
The last couple of output lines are these:
2020-10-04 12:09:14.514 TRACE WEBDAV_ERROR URL request 'PROPFIND chunks/27/e3d4f5208fc0546685b7ea3819b6bf27ba2cd0f03ffc7bfa8810d8a21c7c5a' returned an error (Propfind https://webdav.pcloud.com/Backup/Duplicacy/chunks/27/e3d4f5208fc0546685b7ea3819b6bf27ba2cd0f03ffc7bfa8810d8a21c7c5a: EOF)
2020-10-04 12:10:46.558 INFO WEBDAV_RETRY URL request 'GET chunks/b6/717cc55e12002476b0014d7d5823ad5ae24c2d2b21972083dfbdbc345dc142' returned status code 403
2020-10-04 12:12:55.755 TRACE WEBDAV_ERROR URL request 'GET chunks/67/6f86190b93f27e2accba81de1a6f25d56b9b7f9a9f3251d4053a859bbe0d15' returned an error (Get https://webdav.pcloud.com/Backup/Duplicacy/chunks/67/6f86190b93f27e2accba81de1a6f25d56b9b7f9a9f3251d4053a859bbe0d15: EOF)
2020-10-04 12:13:03.177 TRACE WEBDAV_ERROR URL request 'PROPFIND chunks/4d/bfcd761fe3261502627c66fee6df4ff43292717f4498c42cbe8e407a0a6e36' returned an error (Propfind https://webdav.pcloud.com/Backup/Duplicacy/chunks/4d/bfcd761fe3261502627c66fee6df4ff43292717f4498c42cbe8e407a0a6e36: EOF)
2020-10-04 12:15:51.295 TRACE WEBDAV_ERROR URL request 'GET chunks/b6/79a17118b5c201935da2fd7470f570e31743dd05ff2d3018edd3057f42992c' returned an error (Get https://webdav.pcloud.com/Backup/Duplicacy/chunks/b6/79a17118b5c201935da2fd7470f570e31743dd05ff2d3018edd3057f42992c: EOF)
What do I do with this?
Edit:
@gchen, regarding the 403 errors I found this:
In WebDAV, the 403 Forbidden response will be returned by the server if the client issued a PROPFIND request but did not also issue the required Depth header or issued a Depth header of infinity
I don’t know whether the pcloud webdav interface adheres to the RFC, but it might be worth checking whether duplicacy might sometimes issue a faulty “Depth header” (whatever that is)…