What is Google Drive File Stream and how to use?
 I will use the abbreviation
I will use the abbreviation gdfs from now on when referring to Google Drive File Stream.
Google Drive File Stream is different than the personal Google Drive Backup and Sync.
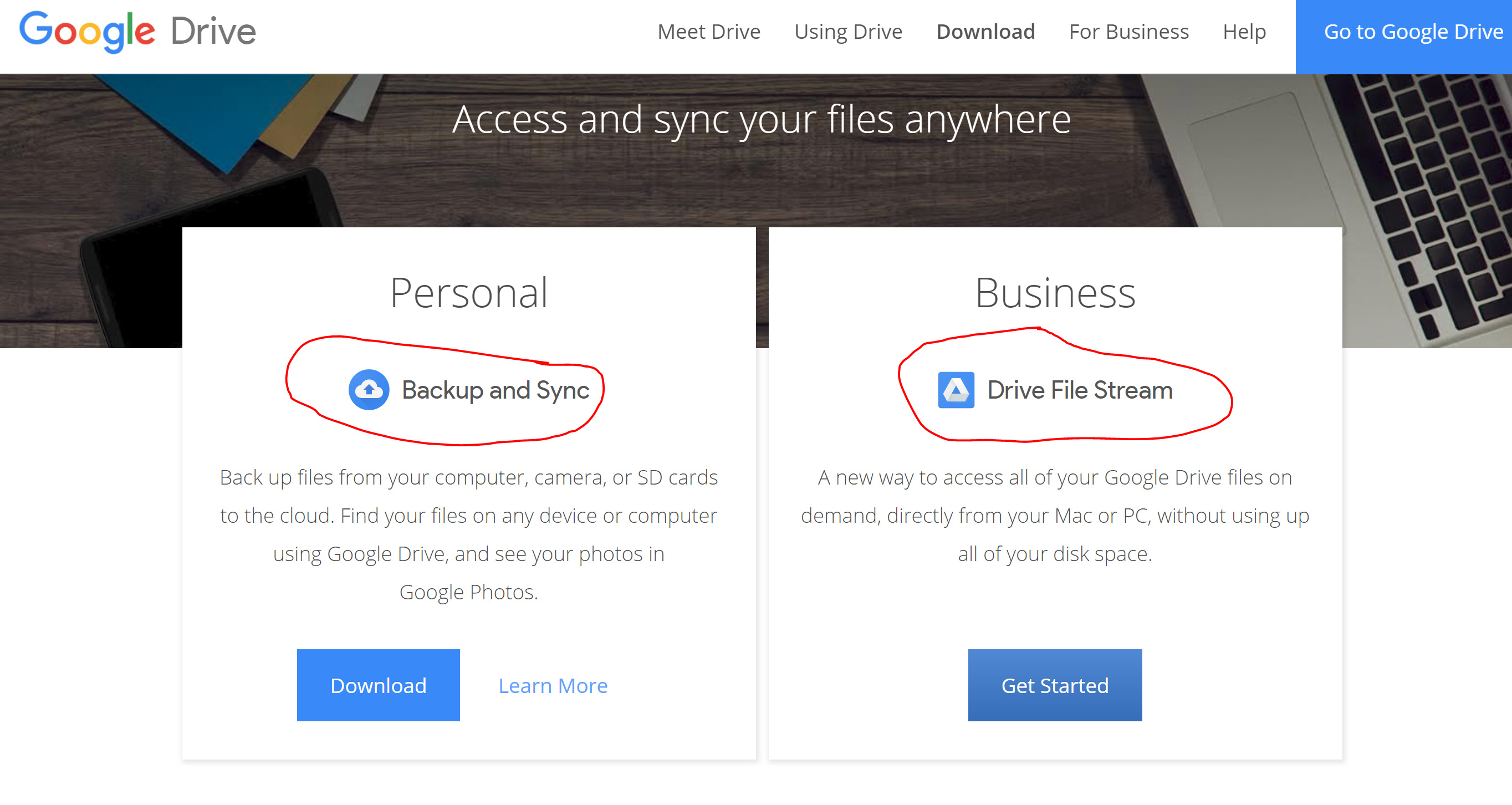
It’s a program which mounts the Google Drive contents as a local drive.

What it does is cache the metadata of the files you have online, to your local drive, and you can see and access those files using windows explorer as if they were locally on your disk.

When you open a file, gdfs downloads that file to your computer, and then stores it for future uses. A file is downloaded only once, then cached.
The storage space used by gdfs is generally less than if using the personal Google Drive Backup and Sync, because with Google Drive Backup and Sync one has to download everything offline, while gdfs downloads only the files you open.
of course you can select whole folders in gdfs for offline access. These folders are stored on disk and fully managed by gdfs
The relation with  is that
is that gdfs is a way faster alternative to using the Google Drive web-api, which is used when you init storages with gcd://some/path.
How to use Google Drive File Stream with
Since gdfs is a normal system drive, you init the storage as a Local Disk
duplicacy init -e my-repository-gdfs "G:\My Drive\backups\duplicacy"
and then all the commands are run normally.
Can I also backup a repository with web-api to the same storage?
Of course!
duplicacy init -e my-repository-web-api "gcd://backups/duplicacy"
the only different thing is the storage path.
Here’s the gcd web repository .duplicacy/preferences file:
[
{
"name": "default",
"id": "tbp-pc",
"storage": "gcd://backups/duplicacy",
"encrypted": true,
"no_backup": false,
"no_restore": false,
"no_save_password": false,
"keys": null
}
]
And the gdfs repository .duplicacy/preferences file:
[
{
"name": "default",
"id": "tbp-pc",
"storage": "G:/My Drive/backups/duplicacy",
"encrypted": true,
"no_backup": false,
"no_restore": false,
"no_save_password": false,
"keys": null
}
]
How fast is gdfs?
That is for you to decide.
Running check command on all repositories
First check run (i believe most chunks are already cached
PS C:\duplicacy repositories\tbp-v> date; .\.duplicacy\z.exe check -all -tabular; date
Saturday, 13 July, 2019 14:57:40
Storage set to G:/My Drive/backups/duplicacy
Listing all chunks
6 snapshots and 213 revisions
Total chunk size is 2325G in 503308 chunks
All chunks referenced by snapshot macpiu-pro at revision 1 exist
All chunks referenced by snapshot macpiu-pro at revision 4 exist
All chunks referenced by snapshot tbp-bulk at revision 1 exist
[...]
All chunks referenced by snapshot tbp-bulk at revision 56 exist
All chunks referenced by snapshot tbp-nuc at revision 1 exist
[...]
All chunks referenced by snapshot tbp-nuc at revision 879 exist
All chunks referenced by snapshot tbp-pc at revision 3231 exist
All chunks referenced by snapshot tbp-pc at revision 3247 exist
All chunks referenced by snapshot tbp-v at revision 1 exist
[...]
All chunks referenced by snapshot tbp-v at revision 862 exist
All chunks referenced by snapshot nope at revision 155 exist
[...
All chunks referenced by snapshot nope at revision 602 exist
snap | rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
macpiu-pro | 4 | @ 2019-06-20 16:43 | 169818 | 152,869M | 29379 | 136,111M | 951 | 3,961M | 953 | 3,972M |
macpiu-pro | all | | | | 29532 | 136,538M | 9898 | 46,574M | | |
snap | rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
tbp-bulk | 56 | @ 2019-07-10 01:02 | 112933 | 1602G | 331293 | 1590G | 8301 | 40,304M | 8301 | 40,304M |
tbp-bulk | all | | | | 417670 | 1970G | 399697 | 1890G | | |
snap | rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
tbp-nuc | 879 | @ 2019-07-13 10:00 | 95159 | 14,035M | 4623 | 15,529M | 5 | 3,533K | 5 | 3,533K |
tbp-nuc | all | | | | 23937 | 90,876M | 17240 | 62,703M | | |
snap | rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
tbp-pc | 3247 | @ 2018-11-30 13:57 | 123147 | 15,904M | 2154 | 6,129M | 143 | 288,246K | 145 | 290,560K |
tbp-pc | all | | | | 2278 | 6,371M | 1870 | 5,315M | | |
snap | rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
tbp-v | 862 | @ 2019-07-13 13:01 | 60505 | 11,196M | 3083 | 10,858M | 17 | 33,447K | 17 | 33,447K |
tbp-v | all | | | | 50852 | 222,548M | 46168 | 203,218M | | |
snap | rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
nope | 602 | @ 2019-07-13 10:16 | 245 | 350,321K | 112 | 392,649K | 0 | 0 | 0 | 0 |
nope | all | | | | 1982 | 8,769M | 1977 | 8,757M | | |
Saturday, 13 July, 2019 14:59:41
So that is 2 min 1 sec to check 2.325 GB in 503308 chunks.
And here's the second check run (to show that caching works)
PS C:\duplicacy repositories\tbp-v> date; .\.duplicacy\z.exe check -all -tabular; date
Saturday, 13 July, 2019 15:00:13
Storage set to G:/My Drive/backups/duplicacy
Listing all chunks
6 snapshots and 213 revisions
Total chunk size is 2325G in 503308 chunks
All chunks referenced by snapshot nope at revision 155 exist
[...]
All chunks referenced by snapshot nope at revision 602 exist
All chunks referenced by snapshot macpiu-pro at revision 1 exist
All chunks referenced by snapshot macpiu-pro at revision 4 exist
All chunks referenced by snapshot tbp-bulk at revision 1 exist
[...]
All chunks referenced by snapshot tbp-bulk at revision 56 exist
All chunks referenced by snapshot tbp-nuc at revision 1 exist
[...]
All chunks referenced by snapshot tbp-nuc at revision 879 exist
All chunks referenced by snapshot tbp-pc at revision 3247 exist
All chunks referenced by snapshot tbp-v at revision 1 exist
[...]
All chunks referenced by snapshot tbp-v at revision 862 exist
snap | rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
nope | 602 | @ 2019-07-13 10:16 | 245 | 350,321K | 112 | 392,649K | 0 | 0 | 0 | 0 |
nope | all | | | | 1982 | 8,769M | 1977 | 8,757M | | |
snap | rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
macpiu-pro | 4 | @ 2019-06-20 16:43 | 169818 | 152,869M | 29379 | 136,111M | 951 | 3,961M | 953 | 3,972M |
macpiu-pro | all | | | | 29532 | 136,538M | 9898 | 46,574M | | |
snap | rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
tbp-bulk | 56 | @ 2019-07-10 01:02 | 112933 | 1602G | 331293 | 1590G | 8301 | 40,304M | 8301 | 40,304M |
tbp-bulk | all | | | | 417670 | 1970G | 399697 | 1890G | | |
snap | rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
tbp-nuc | 879 | @ 2019-07-13 10:00 | 95159 | 14,035M | 4623 | 15,529M | 5 | 3,533K | 5 | 3,533K |
tbp-nuc | all | | | | 23937 | 90,876M | 17240 | 62,703M | | |
snap | rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
tbp-pc | 3247 | @ 2018-11-30 13:57 | 123147 | 15,904M | 2154 | 6,129M | 143 | 288,246K | 145 | 290,560K |
tbp-pc | all | | | | 2278 | 6,371M | 1870 | 5,315M | | |
snap | rev | | files | bytes | chunks | bytes | uniq | bytes | new | bytes |
tbp-v | 862 | @ 2019-07-13 13:01 | 60505 | 11,196M | 3083 | 10,858M | 17 | 33,447K | 17 | 33,447K |
tbp-v | all | | | | 50852 | 222,548M | 46168 | 203,218M | | |
Saturday, 13 July, 2019 15:02:18
So that is 2 min 5 sec to check 2.325 GB in 503308 chunks.
Running backup and prune all
Backup (one ~ 1TB repo) + prune (4 repositories ~ 2.3 TB)
== Starting Duplicacy Backup @ C:\duplicacy repositories\tbp-bulk
= Start time is: 2019-07-10 01:02:28
= Now executting .duplicacy/z.exe -log backup -stats -limit-rate 100000 -threads 1
SUCCESS! Last lines:
=> 2019-07-10 01:53:23.269 INFO BACKUP_STATS Files: 112933 total, 1602G bytes; 27 new, 40,168M bytes
=> 2019-07-10 01:53:23.270 INFO BACKUP_STATS File chunks: 338729 total, 1608G bytes; 8297 new, 40,168M bytes, 40,287M bytes uploaded
=> 2019-07-10 01:53:23.270 INFO BACKUP_STATS Metadata chunks: 15 total, 68,403K bytes; 4 new, 35,484K bytes, 17,378K bytes uploaded
=> 2019-07-10 01:53:23.270 INFO BACKUP_STATS All chunks: 338744 total, 1608G bytes; 8301 new, 40,202M bytes, 40,304M bytes uploaded
=> 2019-07-10 01:53:23.271 INFO BACKUP_STATS Total running time: 00:50:51
=> 2019-07-10 01:53:23.271 WARN BACKUP_SKIPPED 1 file was not included due to access errors
= Now executting .duplicacy/z.exe -log prune -keep 0:1825 -keep 30:180 -keep 7:30 -keep 1:7 -threads 4 -all
SUCCESS! Last lines:
=> 2019-07-10 01:57:34.551 INFO SNAPSHOT_DELETE The snapshot nnnnope at revision 534 has been removed
=> 2019-07-10 01:57:34.557 INFO SNAPSHOT_DELETE The snapshot nnnnope at revision 577 has been removed
=> 2019-07-10 01:57:34.575 INFO SNAPSHOT_DELETE The snapshot nnnnope at revision 579 has been removed
=> 2019-07-10 01:57:34.582 INFO SNAPSHOT_DELETE The snapshot nnnnope at revision 581 has been removed
=> 2019-07-10 01:57:34.587 INFO SNAPSHOT_DELETE The snapshot nnnnope at revision 583 has been removed
=> 2019-07-10 01:57:34.593 INFO SNAPSHOT_DELETE The snapshot tbp-bulk at revision 10 has been removed
== Finished(SUCCESS) Duplicacy Backup @ C:\duplicacy repositories\tbp-bulk
= Start time is: 2019-07-10 01:02:28
= End time is: 2019-07-10 01:57:37
= Total runtime: 55 Minutes 9 Seconds
= logFile is: C:\duplicacy repositories\tbp-bulk\.duplicacy\tbp-logs\2019-07-10 Wednesday\backup-log 2019-07-10 01-02-28_636983173482004646.log
Here’s the full log file: backup-log 2019-07-10 01-02-28_636983173482004646.zip - Google Drive
Notes, Gotchas
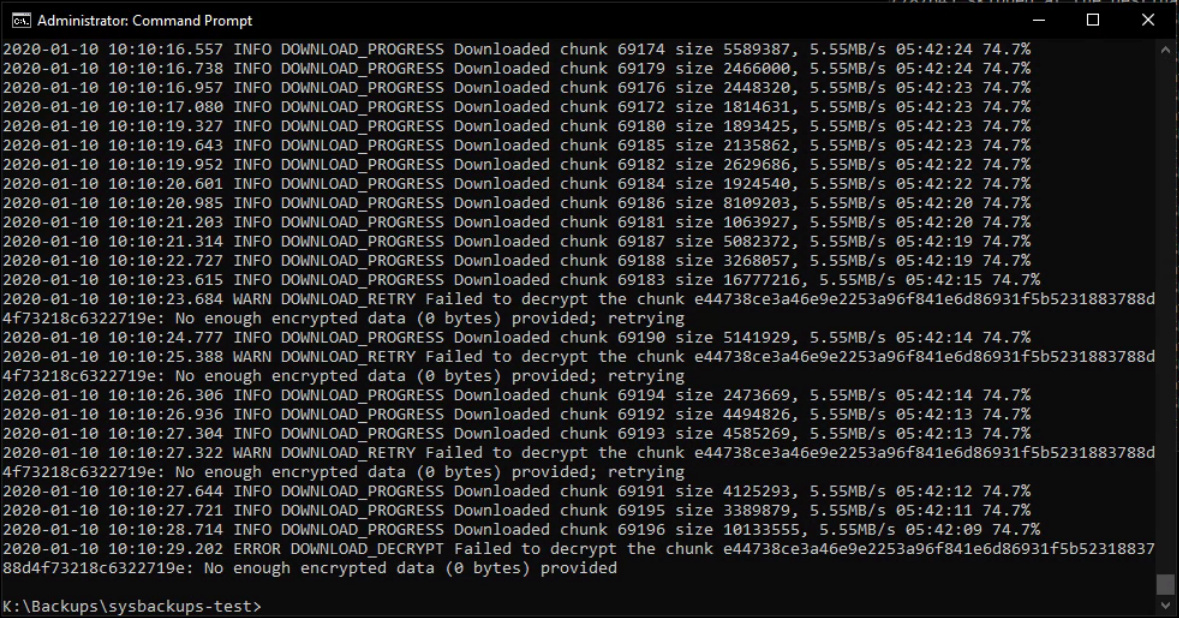
GDFS can fill your HDD in corner cases
Since the chunks creates are copied to the gdfs drive, they will be stored on your real drive in the gdfs cache until they are uploaded, after which they are cleaned up.
This can lead to the case where if your initial backup is big enough (eg. repo size = 600GB, free space = 100GB), will happily backup the data but your computer will run out of space, since syncing to the internet is much slower.
Of course you can just restart the backup, and will resume the incomplete backup, but in case you don’t want to have this issue at all, you can filter some folders out of the initial backups, and add them 1 by 1. By doing this, since will not upload the already backed up files again – but only the new ones, you won’t run out of disk space.
After you’ve uploaded the whole repository and completed the “initial backups” (by repeating the filtering step above as many times as it takes), you can just relax since now your backups (and especially prunes and checks) will be hundred times faster!
 ?
? .
.