You can instruct Duplicacy to run a script before or after executing a command.
For example, if you create a bash script with the name pre-prune under the .duplicacy/scripts directory, this bash script will be run before the prune command starts. A script named post-prune will be run after the prune command finishes.
This rule applies to all commands except init.
On Windows these scripts should have the .bat extension in their names, while on linux they should have no extension.
Beware, with the web gui edition, scripts for backup need to be in ~/.duplicacy-web/repositories/localhost/n/.duplicacy/scripts with n the number of the backup. All others pre-prune, post-copy, etc. need to be in ~/.duplicacy-web/repositories/localhost/all/.duplicacy/scripts.
This is actually pretty easy to do from both linux and windows from a separate batch or sh script that can be used to run all of your scripts in a row. This can also be done in Windows via the Task Scheduler to run one script after another at a certain time. Possibly with cron in linux, but I haven’t messed with cron jobs in a while.
The checks can be separately enabled / disabled, and if an enabled check fails it will produce an error code 1, which will cause Duplicacy to abort the backup.
If you have several backup jobs (like me) and you want to use the same pre-backup script for each, you can create the pre-backup script once (I created in ~/.duplicacy-web/repositories/localhost/), and then symlink it into the individual backup script directories using this command:
The ~/.duplicacy-web/repositories/ folder is a temporary folder. It is generated based on the json file and the filters from the ~/.duplicacy-web/filters/ folder.
So, where could scripts be securely stored in the web version? Something like a ~/.duplicacy-web/scripts/ folder? Or referenced in the json file?
Right, you can put scripts under ~/.duplicacy-web/repositories/*/.duplicacy/scripts but they are not persistent. You’ll need to save a copy somewhere else.
In the feature the web GUI will support pre/post scripts per schedule.
Maybe this area should be better documented (if schedules won’t be added to the Web UI soon).
It’s hard to put various bits and pieces togther. In some threads (now locked) that come up ranked higher in forum search results for post pre scripts there’s outdated info about script paths for Web UI users:
Elsewhere a “mega script” that was suggested, but it can’t run (or can it?) for Web UI jobs, so that’d mean having two sets of backup jobs (one for CLI and another for Web UI) or perhaps using the Web UI only for monitoring/checks.
Yet elsewhere a way to have pre- and post-scripts integrate better with Duplicacy was suggested but not committed (that PR was closed before it was merged).
What’s the difference between “scripts for backup” and “all others” (pre-prune, etc.)? Dooes “all others” mean all scripts not related to specific backup job/number (maybe to check for network connectivity, rather than anything related to files, directories or job targets involved in backup job)?
Does that mean on Linux any script file named pre-$STRING (no extension) would run before and any file named post-$STRING would run after?
I created pre-test and post-test bash scripts, put them under both .duplicacy-web/repositories/localhost/{0-1}/.duplicacy/scripts/ and chmod’ed to 777.
When I run them from shell, they work (echo date to a text file). When I run these jobs 0 and 1 from the Web UI, they don’t get executed. In job logs (available in the Web UI) I see these jobs ran from directories .duplicacy-web/repositories/localhost/{0,1} but the scripts aren’t mentioned in the logs, so looking at the (missing) script output and backup logs, this doesn’t appear to work.
Here’s a wrapper script I’m using with the Web UI on a QNAP NAS to log messages for backup, copy, prune, check, and restore commands to the QNAP Notification Center and to healthchecks.io: DuplicacyLog
A wrapper script is currently easier to hook into the Web UI than pre/post scripts, and has access to the CLI command, output, and exit status.
Is the command “info” the one that do no accept scripts?
when I try to restore data from the web interface, the previous “info” command that is being run, do not load the pre-info script (required to access to an additional storage through webdav-http)
Running /root/.duplicacy-web/bin/duplicacy_linux_x64_2.7.2 [-log -d info -repository /root/.duplicacy-web/repositories/localhost/all webdav-http://username@localhost:9092/]
Also happens with the CLI version when I run the info option.
I have tried with all possible combinations of:
pre
pre-
pre-info
pre-backup
pre-restore
pre-list
pre-check
pre-cat
pre-diff
pre-history
pre-prune
pre-password
pre-add
pre-set
pre-copy
The info command doesn’t support pre/post commands. It is not bound to a repository, unlike other commands, so logically it won’t look for those scripts.
I am wondering if could be included that “info” runs scripts, or maybe changing the “info” command by “list” (that indeed trigger the scripts) within the web restore option, since clearly the fact that info
do not run scripts removes the possibility of restoring from those setups that require a script to run (using additional third party backend to access other storage for instance, like in my case to access webdav-http storage in jottaCloud).
Keep improving this wonderful software. It’s just amazing the web option indeed
I have been using this software since I while and I am always impressed by the amount of features you are adding.
You could use a wrapper script technique similar to that described above: wrapper script:
Move the actual CLI executable from .../.duplicacy-web/bin to another directory and replace it with a custom script that checks the command line arguments for info and, if present, performs your pre-script actions, then execs* the actual CLI.
*On Linux, exec replaces the current process with the new executable, so the wrapper script does not need to handle output and exit status from or signals to the actual CLI. I’m not sure if there’s an exec equivalent for Windows.
Did you ever figure out how to properly use scripts with WebUI? I am looking to set up a very minimal healthchecks.io bash script to run after each successful backup – to catch instances where the backups fail for some reason.
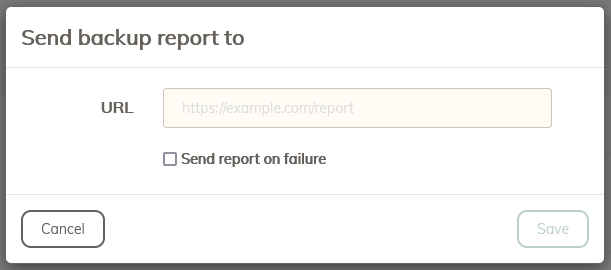
You don’t need a post-script for that… the Web UI has a ‘Send report after completion’ checkbox under each backup ID listed in the Backup tab - you can use this directly with healthchecks.io.
But I would then have to set up an email server (SMTP), which sounds a bit like shooting birds with a cannon. A one-line bash script with a single curl command is what I wanted to run.
The option I’m talking about is the send report under the Backup tab, not the send email under the Schedule tab. Yea, I know, it’s not very obvious there’s a difference.
The former accepts a URL that you can use with healthcheck.io and any schedules running those backup IDs will perform the ping.
More solution than you need and in this case unnecessary but I setup a local mailserver on a little Debian VM where each address corresponds to a forwarding script – it’s handy when a particular service doesn’t support my preferred notification since most support email.
If Duplicacy didn’t support healthcheck.io setup healthcheck@debian.lan to trigger e.g. a python script.
Have smartd send Discord notifications with an email to discord@debian.lan, etc.
It would be good if copy operations could also send healthcheck.io reports as well as backup operations, but I can’t seem to find a way to enable that in the WebUI